Snowflake的架构革命:数据引力时代的企业级AI重构
深度解析Snowflake在LLM时代的战略转型,探讨"数据引力"驱动下的企业级AI架构范式重构,从拓扑倒置到推理经济学的系统工程革命。
No Priors Ep. 139 | With Snowflake CEO Sridhar Ramaswamy </br> https://www.youtube.com/watch?v=UIDMhKgpqkg
引言:拓扑倒置的必然性
在LLM技术席卷企业级市场的当下,Snowflake正在经历一场深刻的系统工程重构。这场变革的核心,并非简单的产品功能叠加,而是对数据平台本体论的根本性重新定义。CEO Sridhar Ramaswamy所主导的战略转型,实质上是对数据引力(Data Gravity)这一物理约束的工程学响应——将计算从模型侧迁移至数据侧,构建一个内嵌推理能力的语义内核。
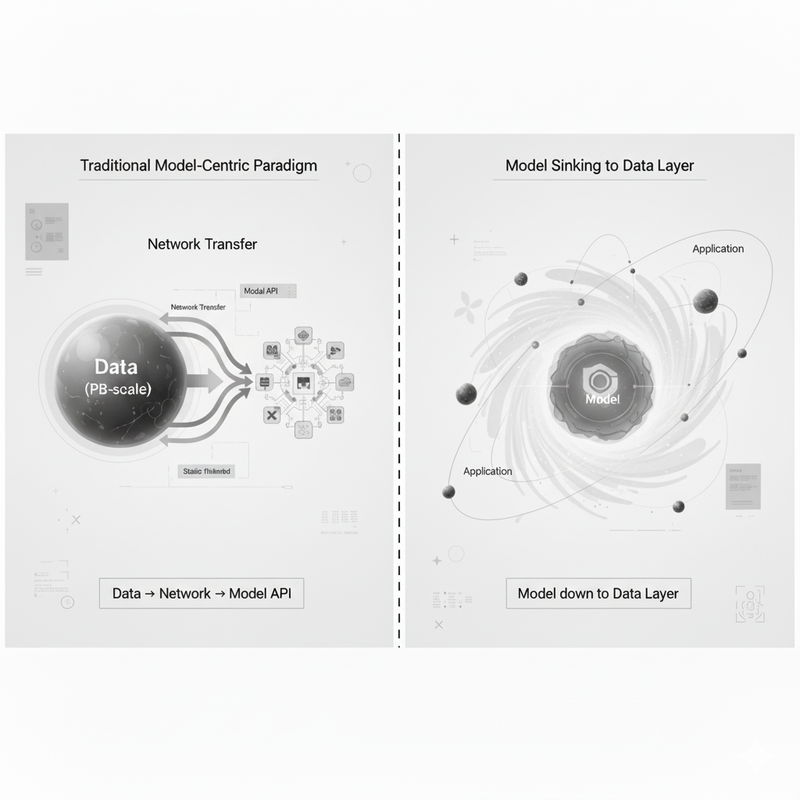
这不仅是商业策略的调整,更是对企业级AI架构范式的拓扑重构。
一、数据引力的物理实现:从ETL到就地推理
架构倒置的工程逻辑
传统的 Model-Centric 范式试图将PB级数据搬运至模型API进行推理,这种对抗物理定律的架构在企业场景下已不可持续。当数据规模达到一定量级,它便表现出类似大质量天体的引力特征,吸引应用程序向其靠拢。 
Snowflake的战略转型——Bring Model to Data——正是对这一约束的理性回应。
这种拓扑倒置基于三重工程考量:
延迟优化(Latency):跨网络的数据传输在RAG(Retrieval-Augmented Generation)流程中引入了不可接受的首词延迟(Time-to-First-Token, TTFT)。Snowflake通过Cortex/Intelligence将推理引擎下沉至存储层邻域,实现了零拷贝(Zero-Copy)的计算环境。
带宽经济学:PB级数据的持续同步会产生巨大的I/O开销。利用Micro-Partitions(微分区)的元数据驱动剪枝(Metadata-Driven Pruning),系统可以在压缩的列式存储上直接运行LLM,将Retrieval阶段转化为存储引擎内部的高效元数据查找。
合规边界(Compliance/PII):高敏感度的财务或销售数据一旦离开数仓,便会破坏上下文安全性(Context Security)。就地推理彻底消除了数据在传输过程中的暴露面。
从存储介质到语义内核
Snowflake的架构演进标志着数据平台正从单纯的归档系统向具备认知能力的”Semantic Kernel”转变。当LLM成为数据库的原生操作,Context Window能够无缝接入企业核心数据,而无需经历繁琐的序列化与跨系统传输。这种紧凑性(Compactness)直接决定了系统的整体熵值——更短的数据路径意味着更低的信息损耗和更高的语义保真度。
二、信息检索的回归:混合拓扑与反馈闭环
RAG vs Context Window:参数记忆的边界
关于 LLM 的 Context Window 是否会终结 RAG 的争论,往往陷入了对参数记忆(Parametric Memory)的盲目迷信。即便模型能够处理百万级 Token 的上下文,这种能力也无法替代 RAG 的核心价值。
RAG 实质上是将 Information Retrieval 作为 LLM 的外挂海马体,构建了参数知识与动态数据的正交互补系统。
这种架构选择基于两个根本性约束:
- 时效性鸿沟:模型参数在训练后即被冻结,无法感知实时更新的企业数据(如库存变动、最新工单)
- 成本-精度权衡:将全量企业文档塞入 Context Window 不仅成本高昂,还会因注意力稀释导致检索精度下降
因此,RAG 不是 Context Window 的过渡方案,而是企业级 AI 的必然选择——它将静态的参数记忆与动态的检索机制解耦,使系统能够在不重新训练的前提下持续吸收新知识。
超越向量迷信的工程视角
Sridhar Ramaswamy的搜索背景(Google Search/Neeva)为Snowflake的AI战略注入了关键洞察:
搜索的本质不在检索(Retrieval),而在排序(Ranking)与反馈闭环(Feedback Loop)。
这是对当前RAG实现的精准批判——许多系统过度迷信高维向量空间的语义匹配,却忽视了倒排索引在精确匹配上的不可替代性。
单纯的Dense Vector Search在处理特定实体查询(如SKU、工号、特定错误代码)时表现出显著的精度衰减。企业级场景需要的是Hybrid Search(混合检索)拓扑:
- 稀疏向量(Sparse Vectors)保留倒排索引的精确性
- 稠密向量(Dense Vectors)捕捉语义关联
- 重排模型(Reranker)引入类似PageRank的权威性评估机制

数据飞轮:从静态知识库到动态学习系统
更深层的架构创新在于Evaluation Loop(评估循环)的建立。传统搜索引擎通过点击流数据优化排序算法,而企业级LLM应用长期缺乏类似的质量打分机制。Snowflake提出的解决方案是将用户交互反馈(对AI回答的修正、引用的点击、采纳率)回流至数仓,用于微调嵌入模型或优化检索策略。
这种反馈机制构建了一个内部的数据飞轮:非结构化的交互数据被转化为结构化的优化信号,使得RAG效果不再受限于模型参数的静态记忆,而是随企业知识积累而线性增长。 
这是通往垂直领域 AGI 的隐形阶梯——不是依靠更大的通用模型,而是通过持续的域内反馈实现知识进化。
这一路径揭示了企业级 AI 的独特优势:通用大模型受限于互联网语料的广度诅咒,而垂直领域系统通过高质量反馈的密度优势实现超越。当系统能够持续学习”哪些检索结果真正解决了业务问题”,它便获得了通用模型永远无法企及的领域专家级判断力。这不是参数规模的竞赛,而是知识精炼效率的比拼——Snowflake 的数据飞轮正是这种效率的物理实现。
三、确定性的救赎:元数据约束与代码执行
Text-to-SQL的语义鸿沟
LLM的概率生成特性与企业数据分析对确定性的要求之间,存在天然的张力。这正是Sridhar强调 No YOLO AI(拒绝碰运气式AI)的根本原因。
在Text-to-SQL任务中,这种张力表现得尤为剧烈:通用LLM极易产生”语法正确但逻辑谬误”的 Silent Failure(静默失败)——Join路径错误或字段语义误读导致的结果在业务层面南辕北辙。
Cortex Analyst的解决方案
Snowflake试图跨越这一鸿沟的策略在于利用Metadata(元数据)作为约束条件:
Semantic Layer(语义层)构建:通过对Table Schema和Query History的深度学习,将自然语言的模糊意图映射为严格的SQL逻辑。这是从非结构化空间向结构化空间的降维过程。
Coding Agents模式:不让LLM直接”猜测”答案,而是采用Code Interpreter路径——让LLM充当Router(路由)和Logic Synthesizer(逻辑合成器),在沙盒环境(Snowpark)中生成并执行Python/SQL代码。
确定性反馈回路:利用解释器的确定性来对冲模型生成的随机性。这种Agentic Workflow将单步推理转化为多步规划与执行,通过代码执行反馈消除随机性噪声。
Snowflake的优势在于其掌握了Data Lineage(数据血缘)的全貌。将Schema、约束条件及历史查询日志注入到Agents的上下文中,系统可以将意图约束在合法的逻辑空间内。这是将非结构化意图转化为结构化执行的唯一稳健解法。
四、推理经济学的突破:SwiftKV与成本革命
KV Cache的压缩哲学
随着Context Window的扩大,Attention机制的二次方复杂度使得推理成本成为企业级AI普及的主要瓶颈。Snowflake Research推出的SwiftKV技术从底层算子层面重构了推理的经济学模型:
- 模型重布线(Model Rewiring):在保持精度的前提下重组计算图
- 知识保留自蒸馏(Knowledge-Preserving Self-Distillation):压缩KV Cache而不损失语义能力
- 性能指标:降低75%推理成本,提升2x吞吐量
ROI曲线的重塑
这种优化不仅是算法改进,更直接改变了LLM服务的投资回报率:
迭代式开发成为可能:降低单次推理的边际成本,允许工程师在同样预算约束下进行更多轮次的MVP验证和Evaluation Loop迭代。正如Sridhar建议的”从小模型、小场景入手”,这种基于Low-hanging fruit(低垂果实)的务实ROI观,将AI系统构建视为软件工程问题而非炼金术。
全量文档库的实时RAG:成本降低意味着企业可以更频繁地运行长上下文推理任务,不再需要为节省Token而过度裁剪Prompt,从而释放模型处理复杂逻辑的潜力。
五、权限继承与治理边界:Agent Runtime的架构优势
从Dashboard到智能体的范式转移
传统BI工具将多维数据降维投影至二维平面,这是信息的有损压缩。Snowflake的Raven及其Coding Agents实践表明,未来的数据消费界面将是具备多步推理能力的智能体——不仅执行查询,还能整合CRM、工单系统等多模态数据,完成从”数据读取”到”业务行动”的闭环。
业务行动闭环的价值重构
这种范式转移的深层意义在于决策延迟的消除。传统流程中,数据分析师生成报表 → 业务人员解读 → 决策者批准 → 执行团队行动,这条链路充满了信息衰减与时间损耗。
这不再是”数据可视化”,而是”数据驱动的自主行动”——Agent 成为连接洞察与执行的神经中枢。
对于企业而言,这意味着从”事后分析”向”实时干预”的跃迁。当 AI 能够在检测到客户流失信号的瞬间自动生成挽留方案并推送至销售团队,数据的价值便从”支持决策”升级为”驱动行动”。这是 Snowflake 构建 AI Data Cloud 的终极愿景——让数据不仅能被理解,更能被执行。
安全边界的收敛
Agent引入了新的治理挑战:在LangChain等外部框架中复刻企业RBAC(基于角色的访问控制)极其困难。Snowflake的架构优势在于Agent Runtime天然继承底层权限体系——当Agent在数据平台内部运行时,每次数据访问都受行级安全策略(Row-Level Security)约束,解决了AI应用中最棘手的权限泄露问题。
这种架构将安全边界收敛至单一控制平面,使企业无需在灵活性与合规性之间做零和博弈。零拷贝共享(Zero-Copy Sharing)技术进一步确保了即使在跨组织协作场景下,ACLs(访问控制列表)也能原生继承。
异构数据源的统一治理
在实际企业场景中,这种权限继承的价值尤为突出。以 SAP、Salesforce 等异构系统为例,传统架构需要在每个数据消费端重新实现权限逻辑,导致治理碎片化。
Snowflake 的 Data Fabric 通过零拷贝共享机制,使得 SAP 的财务数据、Salesforce 的客户信息能够在不离开原始存储的前提下,被 AI Agent 统一访问——且每次访问都自动继承源系统的权限策略。
这种架构消除了”数据湖泊化”(Data Swamp)的风险:数据无需被复制到中央仓库即可参与推理,权限标签如影随形,使得合规审计从”事后追溯”转变为”实时约束”。对于金融、医疗等强监管行业,这是 AI 系统从实验室走向生产环境的必要条件。
六、辩证的视角:隐忧与边界
厂商锁定的拓扑封闭性
尽管”Bring Model to Data”架构展现出极高效能,但不可忽视其 Vendor Lock-in(厂商锁定)风险。
Snowflake的AI Data Cloud构建了高度集成的Data Fabric,虽然解决了异构数据的零拷贝共享和权限继承问题,但也导致潜在的锁定风险。
具体表现为:
- 推理逻辑与底层存储的深度耦合
- 向量索引(Cortex Search的100M行限制)与平台绑定
- 迁移成本趋近无穷大
语义保真度的根本性挑战
Data Gravity的反面是Data Quality(数据质量)。
AI无法凭空消除”语义鸿沟”(Semantic Gap)——如果企业原始数据缺乏清晰语义定义或存在严重脏数据,Cortex Intelligence也仅是在加速”Garbage Out”的过程。
未来的竞争焦点将是 Semantic Fidelity(语义保真度) 的竞争:如何确保数据在从存储介质流向推理引擎的过程中,其业务语义、合规标签和上下文约束不发生畸变。这需要的不仅是技术栈的完善,更是企业数据治理能力的根本性提升。
结语:系统工程的范式转移
Snowflake在Sridhar Ramaswamy领导下的演进,代表了企业级LLM架构从”以计算为中心”向”以数据为引力中心”的深刻转变。这场变革的核心要素包括:
- 拓扑倒置:通过数据引力整合计算资源,实现就地推理
- 混合检索:IR技术的回归,构建精确性与语义性并存的检索拓扑
- 元数据约束:利用Schema和Lineage确保推理可靠性
- 底层优化:通过SwiftKV等技术重塑经济模型
- 权限继承:Agent Runtime的原生安全边界
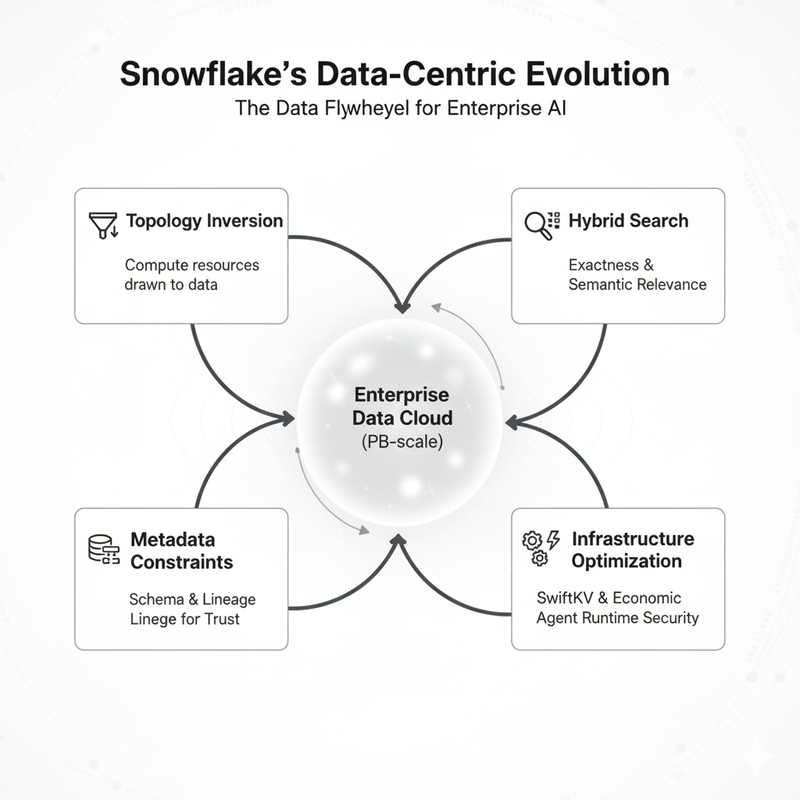
对于系统架构师而言,这意味着关注点必须从单纯的模型选型,转移到对数据拓扑、检索管道及评估体系的整体设计。在2025年的技术语境下,结构化数据与非结构化语义的深度融合,企业知识与反馈机制的持续进化,才是构建企业级智能护城河的关键所在。
Snowflake的实践表明:企业级AI不是关于谁拥有最大的模型,而是关于谁能在延迟、成本、合规与语义保真度之间找到最优解。这是一场系统工程的革命,而非单纯的算法竞赛。