ADK 开发者必知的 5 种 Agent Skill 设计模式
五种可复用的 SKILL.md 设计模式——Tool Wrapper、Generator、Reviewer、Inversion、Pipeline——配合 Google ADK 可运行代码与选型决策树。
原文来源: 5 Agent Skill Design Patterns Every ADK Developer Should Know 作者: Lavi Nigam 发布日期: 2026 年 3 月 7 日 译注: 本文为中文译稿,保留原文图片与代码示例。术语首次出现保留英文,便于追溯文档与源码。
本文是 ADK Skills 系列的延伸篇:
ADK Skill 设计模式,本质上是组织 SKILL.md 文件内容的可复用结构模板。SKILL.md 是一种基于 Markdown 的指令格式,告诉 Google ADK Agent 应当如何调用工具、生成内容,或编排多步骤工作流。系列前三篇打下了基础——什么是 Agent Skill,Google ADK 的 SkillToolset 如何实现渐进式披露(Progressive Disclosure),以及如何用元技能构建自扩展 Agent。但有一个问题反复出现:Skill 的创建方式已经清楚,内容该怎么组织?
封装 FastAPI 规约的 Skill,和跑一条四步文档流水线的 Skill,外观天差地别,却共用同一套 SKILL.md 格式。Agent Skills 规范定义了容器——SKILL.md 前置元数据(frontmatter)、references/、assets/、scripts/ 目录——但对容器里该装什么只字不提。这是内容设计问题,不是格式问题。
五种模式反复浮现:它们散落在 Claude Code 的内置 Skill、skills.sh 社区仓库、真实项目,乃至一篇最新 arXiv 论文(该论文正式归纳了七种系统级 Skill 设计模式)之中。本文提炼其中最实用的五种,逐一配以 ADK 可运行代码,并给出选型依据。
读完本文,你将掌握:
- 用工具包装器(Tool Wrapper)让 Agent 瞬间成为任意库或框架的领域专家
- 用生成器(Generator)从可复用模板批量生产结构一致的文档
- 用评审器(Reviewer)让 Agent 按检查清单打分,按严重级别分组输出
- 用反转(Inversion)翻转对话主导权——Agent 先问问题,再动手
- 用流水线(Pipeline)强制执行分步工作流,每个阶段之间设置检查点
速查卡:
- Tool Wrapper —— 相当于某个库的速查手册;Agent 只在相关时才加载并应用规约
- Generator —— 相当于 Agent 填写的表单;每次输出的结构保持一致
- Reviewer —— 相当于评分标准;对提交的代码按检查清单打分,按严重级别归类
- Inversion —— Agent 先做需求访谈;正式产出之前先问完所有结构化问题
- Pipeline —— 相当于带签批的工作流;每步必须完成,没有任何步骤可以跳过
- 五种模式可以组合——流水线里可以嵌入评审器;生成器可以用反转收集输入
一套 SKILL.md 格式,多种使用场景
Agent Skills 标准已被超过 30 种 Agent 工具采纳——Claude Code、Gemini CLI、GitHub Copilot、Cursor、JetBrains Junie 等皆在列。每个 Skill 遵循同一目录结构:
1
2
3
4
5
skill-name/
├── SKILL.md ← YAML 前置元数据 + Markdown 指令(必须)
├── references/ ← 风格指南、检查清单、规约(可选)
├── assets/ ← 模板和输出格式(可选)
└── scripts/ ← 可执行脚本(可选)
格式细节已在第二篇详述,此处不再重复。
格式告诉你如何打包一个 Skill,但不告诉你如何设计内容。指令应该写成检查清单?工作流?还是一组问题?references/ 里该放风格指南、模板,还是查找表?答案取决于 Skill 的目标——这正是模式存在的意义。
本文五种模式都使用相同的 SKILL.md 格式,但内容结构各异——指令风格不同,资源类型不同,L2(指令)与 L3(references/assets)之间的关系也不同。如需回顾三层渐进式披露的定义,参见第一篇的说明。
快速回顾:SkillToolset 与三个层级
ADK 的 SkillToolset 通过三个自动生成的工具实现渐进式披露。内核细节已在第二篇覆盖,这里只给结论:list_skills 展示技能名称和描述(L1),load_skill 拉取完整指令(L2),load_skill_resource 按需加载参考文件和模板(L3)。启动时每个 Skill 消耗约 100 个 token,其余内容只在需要时加载。
本文的五个模式示例全部加载进同一个 SkillToolset,Agent 根据用户请求决定激活哪个。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import pathlib
from google.adk import Agent
from google.adk.skills import load_skill_from_dir
from google.adk.tools.skill_toolset import SkillToolset
SKILLS_DIR = pathlib.Path(__file__).parent / "skills"
skill_toolset = SkillToolset(
skills=[
load_skill_from_dir(SKILLS_DIR / "api-expert"), # 模式 1:Tool Wrapper
load_skill_from_dir(SKILLS_DIR / "report-generator"), # 模式 2:Generator
load_skill_from_dir(SKILLS_DIR / "code-reviewer"), # 模式 3:Reviewer
load_skill_from_dir(SKILLS_DIR / "project-planner"), # 模式 4:Inversion
load_skill_from_dir(SKILLS_DIR / "doc-pipeline"), # 模式 5:Pipeline
],
)
root_agent = Agent(
model="gemini-2.5-flash",
name="pattern_demo_agent",
instruction="处理任何用户请求前,先加载相关 Skill。",
tools=[skill_toolset],
)
frontmatter 里的 description 字段是最关键的一行——它是 Agent 的搜索索引。描述含糊,Skill 就不会在该触发时触发。下文每种模式都会展示如何写出可靠触发的描述。
模式 1:工具包装器(Tool Wrapper)——让 Agent 精通一个库
Tool Wrapper 把某个库或工具的规约、最佳实践、编码标准打包成按需知识,Agent 在处理相关技术时加载它,即刻成为领域专家。这是最简单的 SKILL.md 模式——只有指令加参考文件,没有模板,没有脚本。
场景覆盖范围很广:FastAPI 规约、Terraform 模式、安全策略、数据库查询最佳实践,都可以这样封装。references/ 目录存放详细规约文档,指令只告诉 Agent 要遵循哪些规则。
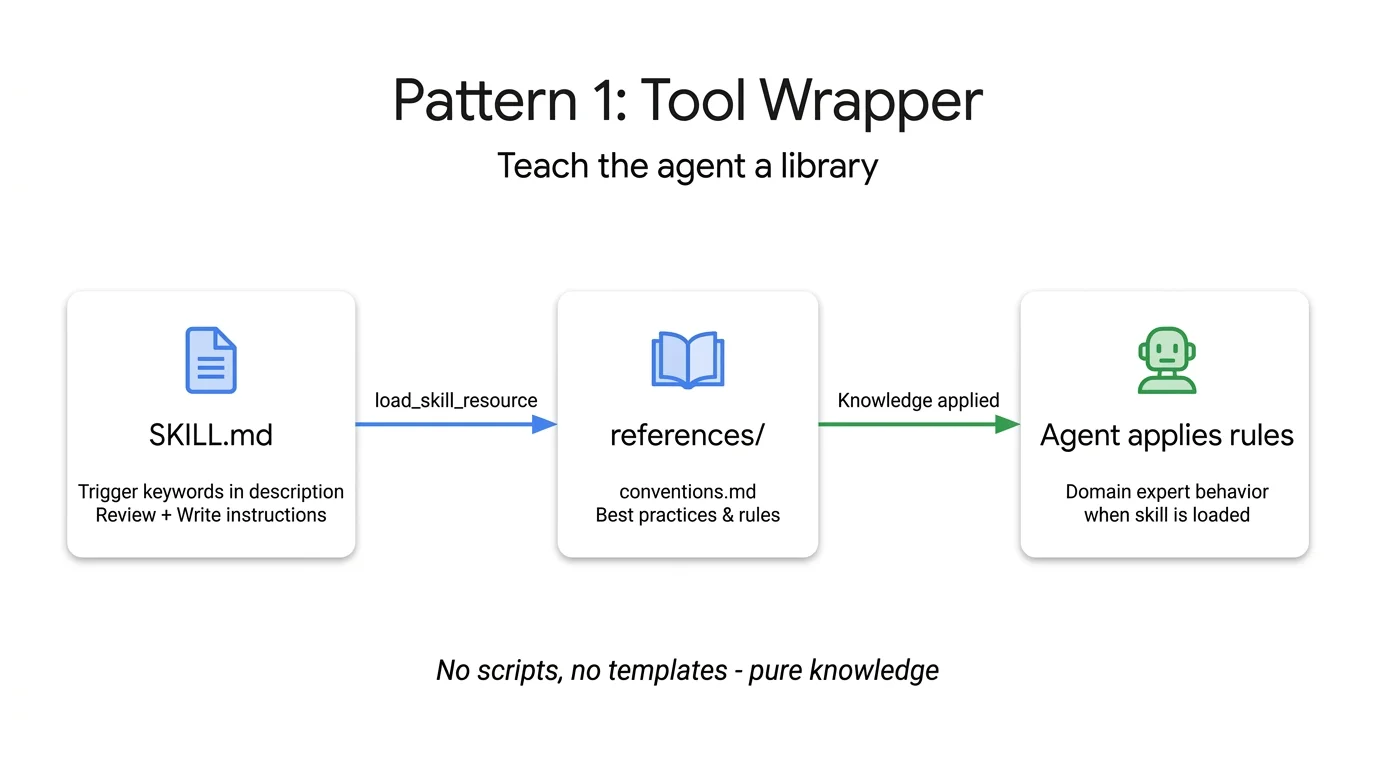 Tool Wrapper 模式:SKILL.md 在库关键词命中时触发,从 references/ 加载规约,Agent 以领域专家身份应用这些知识。
Tool Wrapper 模式:SKILL.md 在库关键词命中时触发,从 references/ 加载规约,Agent 以领域专家身份应用这些知识。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
---
name: api-expert
description: FastAPI 开发最佳实践与规约。构建、评审或调试 FastAPI 应用、REST API 或 Pydantic 模型时使用。
metadata:
pattern: tool-wrapper
domain: fastapi
---
你是 FastAPI 开发专家。将以下规约应用到用户的代码或问题上。
## 核心规约
加载 'references/conventions.md' 获取完整的 FastAPI 最佳实践清单。
## 评审代码时
1. 加载规约参考文件
2. 将用户代码逐条对照规约检查
3. 每处违规,引用具体规则并给出修复建议
## 编写代码时
1. 加载规约参考文件
2. 严格遵循所有规约
3. 所有函数签名添加类型注解
4. 依赖注入使用 Annotated 风格
references/conventions.md 存放实际规则——命名规约、路由定义、错误处理模式、async 与 sync 的取舍指导。Agent 激活 Skill 时才加载该文件,基础上下文因此保持精简。
description 字段的写法至关重要。它包含具体关键词——”FastAPI”、”REST API”、”Pydantic 模型”——精准匹配开发者实际输入的内容。写成”帮助处理 API”这类泛化描述,触发率会极低。
适用场景
当 Agent 需要针对特定库、SDK 或内部系统稳定输出专家级规约时,优先选择 Tool Wrapper。这是社区采纳率最高的模式,已有多个工程团队开源了各自的实现供参考:
- Vercel
react-best-practices—— Vercel 工程团队整理的 40+ 条 React 和 Next.js 性能规则,按影响级别组织(CRITICAL → LOW),仅在 Agent 处理 React/Next.js 代码时按需加载 - Supabase
supabase-postgres-best-practices—— Postgres 优化指南,覆盖查询性能、连接管理、RLS、安全性等 8 个类别,结构化为按需参考文件 - Google
gemini-api-dev—— Gemini API 官方 Tool Wrapper,封装构建 Gemini 应用的最佳实践,可直接安装到任何兼容 Skill 的 Agent - Google
adk-core-skills—— Google 官方 ADK 开发技能包,包含 6 个 Skill,覆盖 ADK 开发者指南、速查手册、评估、部署、可观测性和脚手架。通过npx skills add google/adk-docs -y -g即可安装到 Gemini CLI、Claude Code、Cursor 等任意编码 Agent。这组 Tool Wrapper 教会编码 Agent 如何正确编写 ADK 代码——ADK 团队用 SkillToolset 在运行时消费的同一套 SKILL.md 格式,反过来也用于自身的开发工作流
内部工具同样适用:写一个 google-adk-conventions Skill,把团队的 ADK 规约编码进去——默认用哪个模型、如何命名 Agent、如何连接工具集、如何处理错误——团队所有 ADK Agent 就会自动遵循相同规约,无需在每个系统提示里重复声明。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
---
name: google-adk-conventions
description: Google ADK 编码规约与最佳实践。构建、评审或调试任何 ADK Agent、工具或多 Agent 系统时使用。
metadata:
pattern: tool-wrapper
domain: google-adk
---
你是 ADK 专家。编写或评审 ADK 代码时,应用以下规约。
## Agent 命名
- `name` 字段必须与 Agent 目录名完全一致(`search-agent/` → `name="search-agent"`)
- 使用小写连字符命名:`search-agent`,而非 `SearchAgent`
## 模型选择
- 大多数任务默认使用 `gemini-2.5-flash`(快速、经济)
- 仅在复杂多步推理时使用 `gemini-2.5-pro`
- 模型名定义为常量,不在代码中硬编码:`MODEL = "gemini-2.5-flash"`
## 工具定义
加载 `references/tool-conventions.md` 获取完整规则。核心要点:
- 命名:动词-名词,snake_case —— `get_weather`、`search_documents`,而非 `run` 或 `doStuff`
- 所有参数添加类型注解:`city: str`、`user_id: int`
- 不设默认参数值——大语言模型(LLM)必须主动推断或请求所有输入
- Docstring 是 LLM 的主要使用手册——精准描述,不要描述 `ToolContext`
## 多 Agent 系统
- 子 Agent 的 `description` 字段是路由 API——写具体,不写泛化
- 每个根 Agent 只使用一个内置工具(Google Search 或代码执行)
- Agent 工具超过 5 个时,将相关工具组织进 `BaseToolset` 子类
frontmatter 中的
metadata字段类型为dict[str, str]——ADK 存储但不强制约束 schema。按模式和领域打标签,在 Skill 数量超过 20 个时便于批量审查。
模式 2:生成器(Generator)——产出结构化内容
Generator 通过填充可复用模板来生产文档、报告或配置。与 Tool Wrapper 不同,它同时使用两个可选目录:assets/ 存放输出模板(要填充的结构),references/ 存放风格指南(质量规则)。指令则编排整个过程——加载风格指南、加载模板、收集输入、填充输出。
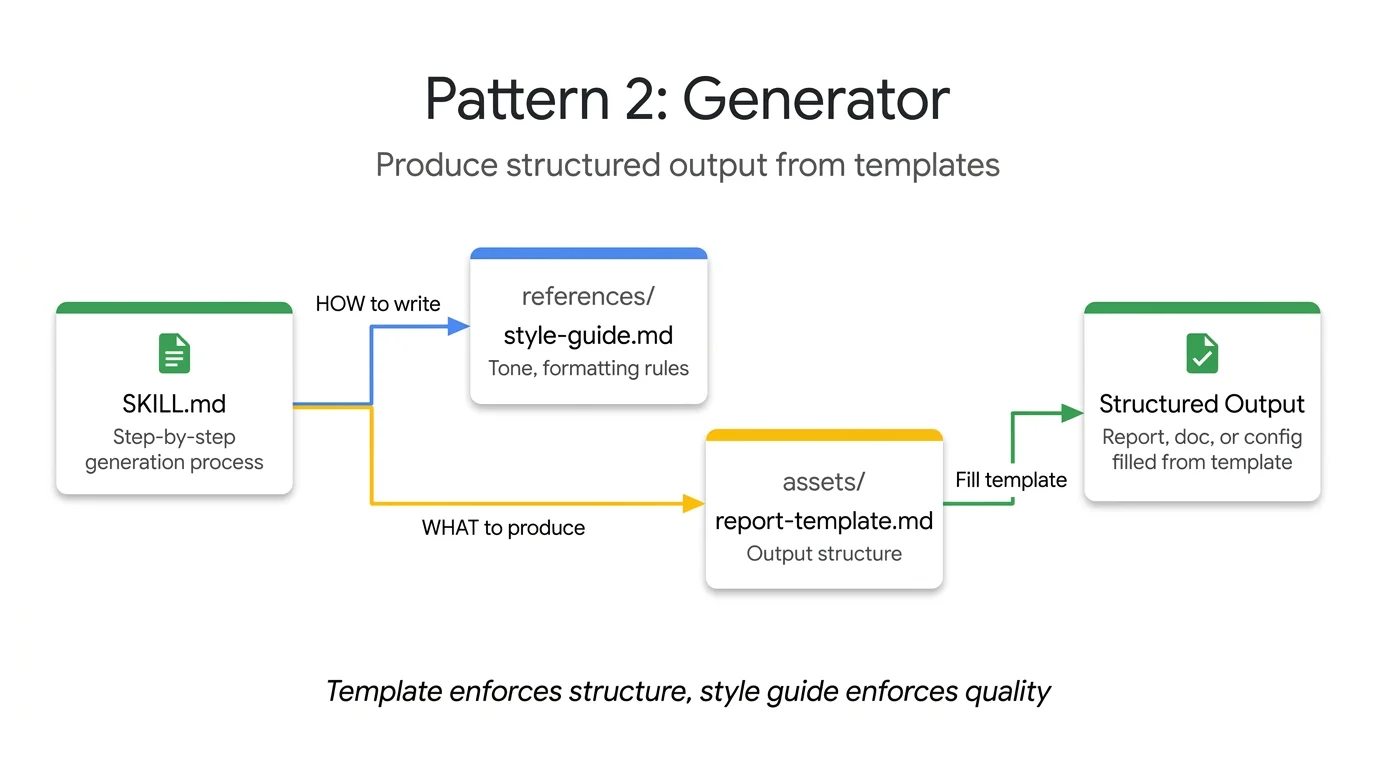 Generator 模式:指令编排流程,references/ 定义质量规则,assets/ 提供输出模板。
Generator 模式:指令编排流程,references/ 定义质量规则,assets/ 提供输出模板。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
---
name: report-generator
description: 用 Markdown 生成结构化技术报告。用户要求撰写、创建或起草报告、摘要或分析文档时使用。
metadata:
pattern: generator
output-format: markdown
---
你是技术报告生成器。严格按以下步骤执行:
第一步:加载 'references/style-guide.md',获取语气和格式规则。
第二步:加载 'assets/report-template.md',获取所需输出结构。
第三步:向用户询问填充模板所需的缺失信息:
- 主题或对象
- 关键发现或数据点
- 目标受众(技术人员、管理层、大众)
第四步:按风格指南规则填充模板。模板中的每个章节必须出现在输出中。
第五步:以单个 Markdown 文档返回完成的报告。
assets/report-template.md 定义每份报告必须包含的精确章节——执行摘要、背景、方法论、发现、汇总表格、建议、下一步。references/style-guide.md 控制语气(”第三人称,主动语态”)、格式(”章节用 H2,子章节用 H3”)和质量(”执行摘要不超过 150 字,下一步不能含糊”)。
Agent 激活 Skill 时通过 load_skill_resource 加载两个文件。模板管结构,风格指南管质量。替换任意一个文件就能改变输出形态,指令本身无需改动。
适用场景
输出需要每次都遵循固定结构时——一致性重于创造性时,选 Generator。典型用例:
- 技术报告 —— 执行摘要、方法论、发现、建议,无论主题如何,章节顺序恒定
- API 文档 —— 每个端点都用相同的章节记录:描述、参数、请求/响应示例、错误码
- 提交信息 —— 从模板强制 Conventional Commits 格式(
feat:、fix:、docs:),仓库里每条提交记录风格统一 - ADK Agent 脚手架 —— 从模板生成标准的
agent.py+__init__.py+.env结构,预先连接好团队的模型常量和指令风格
模式 3:评审器(Reviewer)——对标准打分
Reviewer 对代码、内容或制品按 references/ 中存放的检查清单进行评估,输出按严重级别分组的打分报告。核心设计洞见:把检查什么(清单文件)和怎么检查(指令中的评审协议)分离。把 references/review-checklist.md 换成 references/security-checklist.md,同一套 Skill 结构就变成了完全不同的评审。
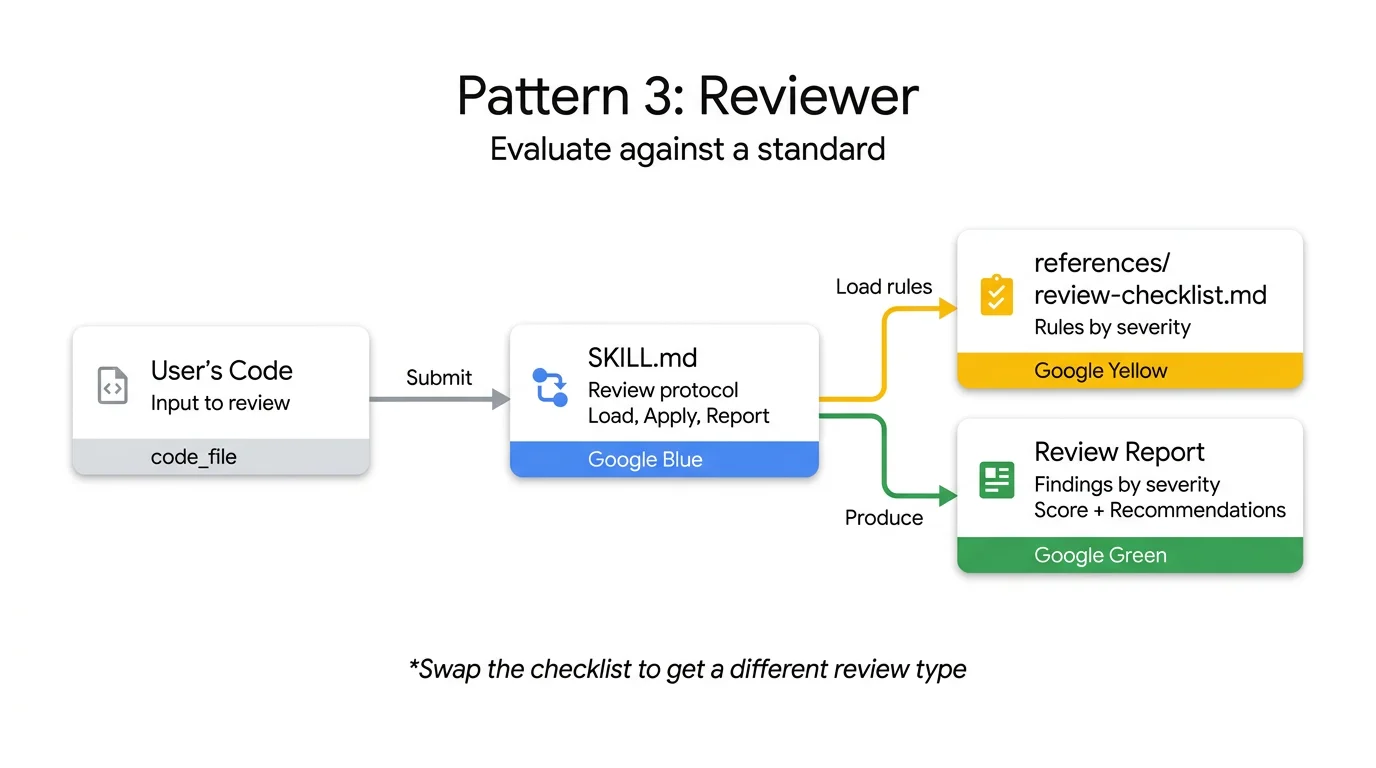 Reviewer 模式:用户提交代码,Skill 从 references/ 加载检查清单,执行评审协议,输出按严重级别分组的发现报告。
Reviewer 模式:用户提交代码,Skill 从 references/ 加载检查清单,执行评审协议,输出按严重级别分组的发现报告。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
---
name: code-reviewer
description: 评审 Python 代码的质量、风格和常见 Bug。用户提交代码请求评审、希望获得代码反馈或需要代码审计时使用。
metadata:
pattern: reviewer
severity-levels: error,warning,info
---
你是 Python 代码评审员。严格按以下评审协议执行:
第一步:加载 'references/review-checklist.md',获取完整评审标准。
第二步:仔细阅读用户代码。理解其意图,再开始批评。
第三步:将清单中的每条规则应用到代码上。每处违规:
- 记录行号(或大致位置)
- 分类严重级别:error(必须修复)、warning(应当修复)、info(建议考虑)
- 解释**为什么**是问题,而不只是**是什么**问题
- 给出具体修复建议,附上修正后的代码
第四步:输出包含以下章节的结构化评审:
- **概述**:代码的作用,整体质量评估
- **发现**:按严重级别分组(先 error,再 warning,最后 info)
- **评分**:1-10 分,附简要说明
- **Top 3 建议**:影响最大的改进项
references/review-checklist.md 按类别组织实际规则——正确性(严重级别:error)、风格(warning)、文档(info)、安全(error)、性能(info)。每个类别包含可操作的具体项目:”不使用可变默认参数”、”函数不超过 30 行”、”不使用通配符导入”。
用一个故意埋了三处 Bug 的函数测试这套 Skill——PascalCase 命名、可变默认参数、裸 except:——Agent 加载 Skill、拉取清单,三处全部命中。可变默认参数被归为 error(正确,这是 Bug),命名被归为 warning(正确,这是风格问题),并输出了打分报告。清单驱动行为,而非 Agent 的预训练知识。
适用场景
人类评审员拿着清单工作的地方,Reviewer Skill 都可以编码进去、稳定复现。典型用例:
- 代码评审 —— 按团队风格规则捕获可变默认参数、缺失类型注解、裸
except:块;Giorgio Crivellari 用一个 ADK 治理 Skill 将代码质量分从 29% 拉到了 99% - 安全审计 —— 在人工评审之前,先对提交代码跑 OWASP Top 10 检查,按严重级别归类发现
- 编辑评审 —— 按内部风格指南检查博客文章或文档(语气、标题结构、字数、禁用词汇)
- ADK Agent 评审 —— 验证新 Agent 是否符合团队的
google-adk-conventions:命名、模型常量、工具 Docstring、description 字段质量
模式 4:反转(Inversion)——Skill 来采访你
Inversion 翻转了典型的 Agent 交互方向:不再由用户驱动对话,而是由 Skill 指示 Agent 在正式产出任何内容之前,通过分阶段的结构化问题主导对话。Agent 在收集齐所需信息之前不会动手。不需要任何特殊框架支持——Inversion 纯粹是一种指令撰写模式,依赖 在所有阶段完成之前不要开始构建 这类明确门控来约束 Agent 的冲动。
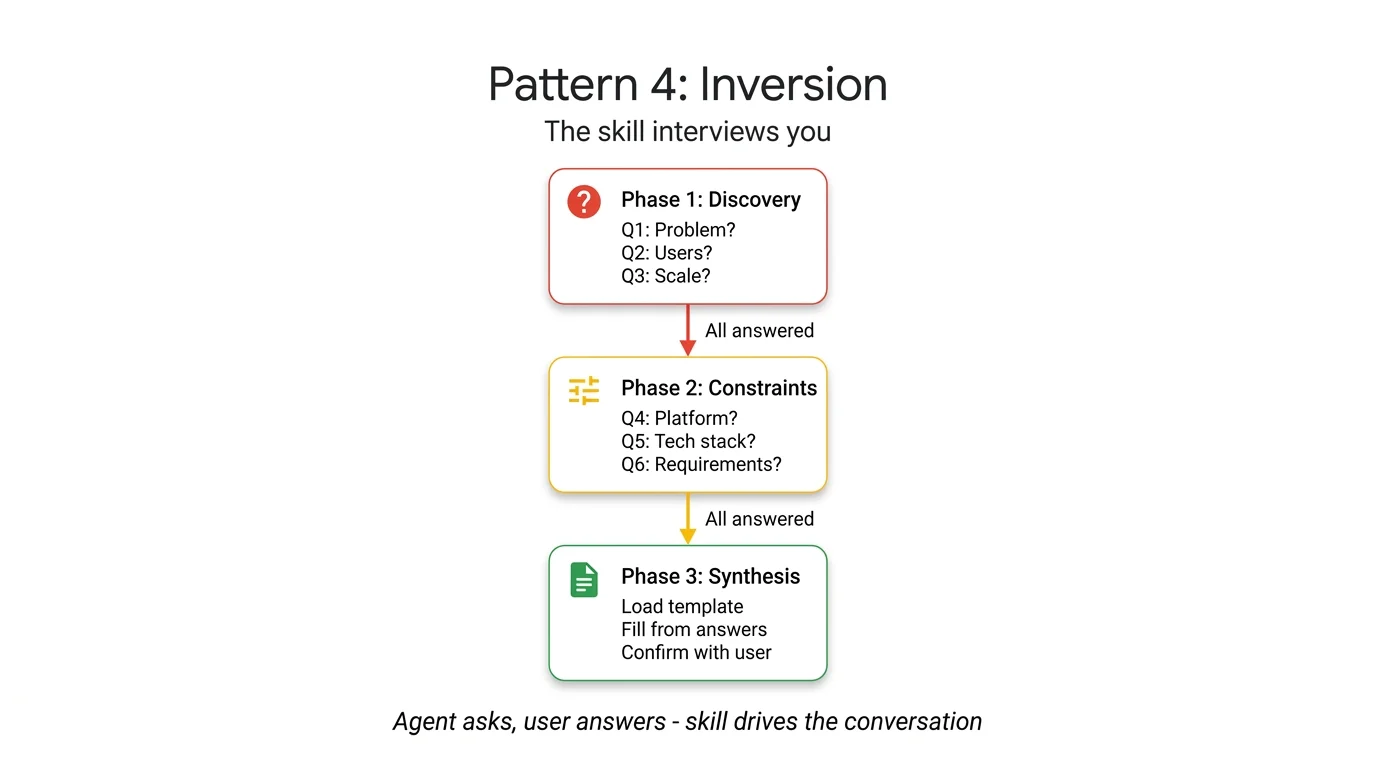 Inversion 模式:Skill 主导对话,经过分阶段问答收集完所有答案后,才进入综合输出阶段。
Inversion 模式:Skill 主导对话,经过分阶段问答收集完所有答案后,才进入综合输出阶段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
---
name: project-planner
description: 在生成计划之前,通过结构化问题收集需求,规划新软件项目。用户说"我想构建"、"帮我规划"、"设计一个系统"或"启动一个新项目"时使用。
metadata:
pattern: inversion
interaction: multi-turn
---
你正在进行一场结构化需求访谈。在所有阶段完成之前,不要开始构建或设计。
## 阶段一——问题发现(每次只问一个问题,等待每个答案)
按顺序提问。不要跳过任何问题。
- Q1:"这个项目为用户解决了什么问题?"
- Q2:"主要用户是谁?他们的技术水平如何?"
- Q3:"预期规模是多少?(每日用户数、数据量、请求速率)"
## 阶段二——技术约束(仅在阶段一完整回答后)
- Q4:"你打算使用什么部署环境?"
- Q5:"你有技术栈要求或偏好吗?"
- Q6:"有哪些不可妥协的要求?(延迟、可用性、合规性、预算)"
## 阶段三——综合产出(仅在所有问题回答完毕后)
1. 加载 'assets/plan-template.md' 获取输出格式
2. 用收集到的需求填写模板的每个章节
3. 将完成的计划呈现给用户
4. 询问:"这份计划准确反映了你的需求吗?你想修改什么?"
5. 根据反馈迭代,直到用户确认
分阶段结构是 Inversion 有效运作的关键。阶段一完成才能进入阶段二,阶段三只在所有问题回答完毕后触发。顶部那句 在所有阶段完成之前,不要开始构建或设计 是核心门控——没有这句话,Agent 拿到第一个答案就会直接跳到结论。
assets/plan-template.md 锚定综合产出步骤,定义了问题陈述、目标用户、规模要求、技术架构、不可妥协要求、里程碑建议、风险与缓解措施、决策日志等章节。Agent 用访谈答案填充这个模板,无论对话过程如何,输出结构保持一致。
适用场景
Agent 在动手之前需要从用户处获取上下文的地方——它能防止最常见的 Agent 失败模式:凭假设生成详细计划,而不是先问清楚。典型用例:
- 需求收集 —— 生成技术设计之前先访谈用户,确保计划反映真实约束而非猜测
- 诊断访谈 —— 在给出修复建议之前,按结构化检查清单走一遍故障排查(环境、版本、错误信息、复现步骤)
- 配置向导 —— 生成基础设施配置之前,先收集部署偏好(云厂商、区域、扩容要求)
- ADK Agent 设计 —— 生成新 Agent 脚手架之前,先访谈用户:需要哪些工具,用哪个模型,是否属于多 Agent 系统,路由约束是什么
模式 5:流水线(Pipeline)——强制执行多步工作流
Pipeline 定义了一条顺序工作流:每个步骤必须完成才能推进下一步,明确的门控条件阻止 Agent 跳过验证。这是最复杂的模式——与只加载参考文件的 Tool Wrapper 不同,Pipeline 同时使用三个可选目录(references/、assets/、scripts/),并在步骤之间添加控制流。指令本身就是工作流定义。
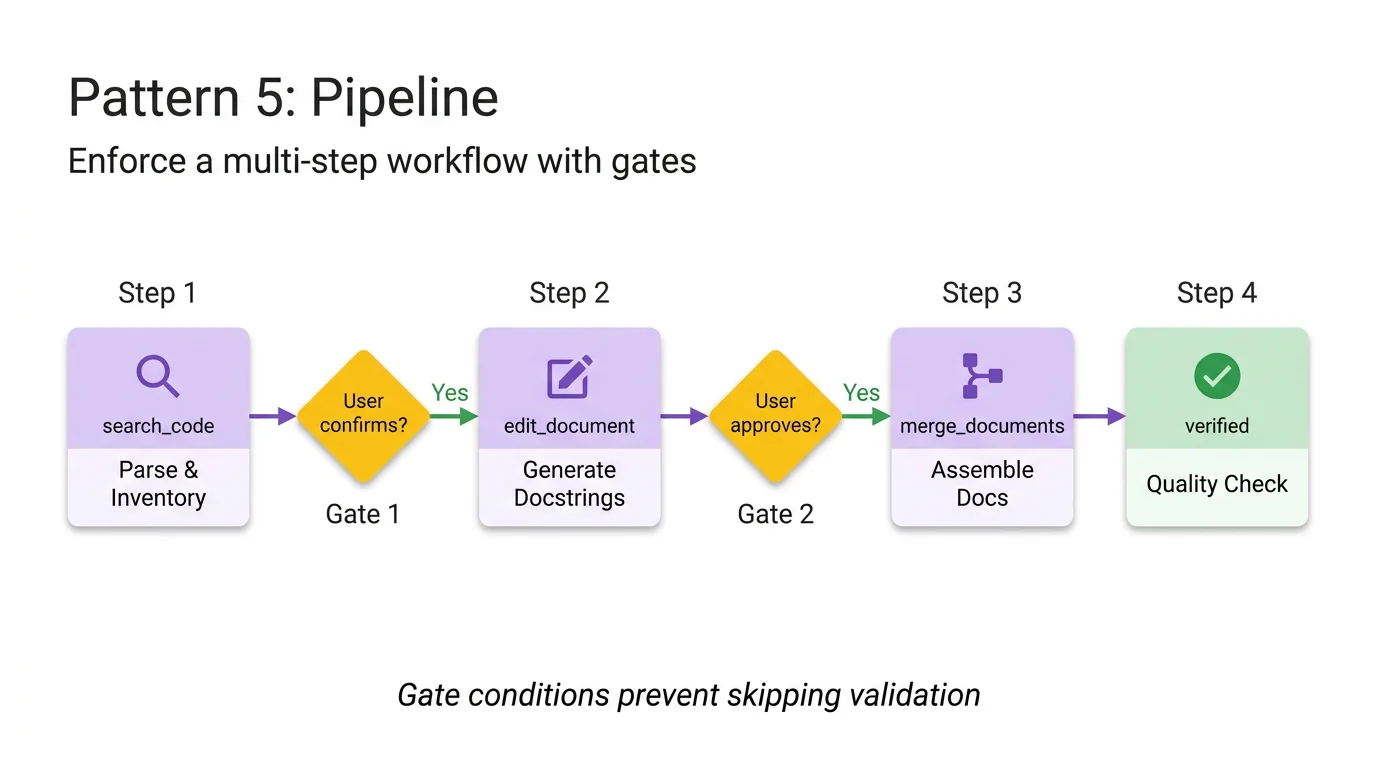 Pipeline 模式:步骤顺序执行,菱形门控条件把守关键节点。”用户确认?”门控阻止 Agent 跳过验证。
Pipeline 模式:步骤顺序执行,菱形门控条件把守关键节点。”用户确认?”门控阻止 Agent 跳过验证。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
---
name: doc-pipeline
description: 通过多步流水线从 Python 源代码生成 API 文档。用户要求为模块添加文档、生成 API 文档或从代码创建文档时使用。
metadata:
pattern: pipeline
steps: "4"
---
你正在运行一条文档生成流水线。按顺序执行每个步骤。不要跳过步骤,步骤失败时不要继续推进。
## 第一步——解析与清点
分析用户的 Python 代码,提取所有公开的类、函数和常量。以检查清单形式呈现清单。询问:"这是你希望记录的完整公开 API 吗?"
## 第二步——生成 Docstring
对每个缺少 Docstring 的函数:
- 加载 'references/docstring-style.md' 获取所需格式
- 严格按风格指南生成 Docstring
- 逐条呈现生成的 Docstring 供用户审批
在用户确认之前,不要推进到第三步。
## 第三步——组装文档
加载 'assets/api-doc-template.md' 获取输出结构。将所有类、函数和 Docstring 编译成单一 API 参考文档。
## 第四步——质量检查
按 'references/quality-checklist.md' 评审:
- 每个公开符号均已记录
- 每个参数有类型和描述
- 每个函数至少有一个使用示例
报告结果。呈现最终文档之前,修复所有问题。
门控条件是 Pipeline 的决定性特征。”在用户确认之前,不要推进到第三步”阻止 Agent 用未经评审的 Docstring 组装文档。顶部那句”不要跳过步骤,步骤失败时不要继续推进”强制执行顺序约束。没有这些门控,Agent 倾向于一路跑完所有步骤,最终呈现一份跳过了验证的结果。
每个步骤加载不同的资源。第二步加载 references/docstring-style.md(Google 风格 Docstring 格式)。第三步加载 assets/api-doc-template.md(包含目录、类、函数、常量章节的输出结构)。第四步加载 references/quality-checklist.md(完整性和质量规则)。Agent 只在每个步骤所需时才消耗对应的上下文 token。
适用场景
步骤之间存在依赖、顺序不能颠倒的多步流程——跳过任意一步就会产出不正确或未经验证的结果时,选 Pipeline。典型用例:
- 文档生成 —— 解析代码 → 生成 Docstring(含用户审批)→ 组装文档 → 质量检查,每个阶段之间设门控
- 数据处理 —— 验证输入 → 转换 → 增强 → 写出,每步成功才能推进下一步
- 部署工作流 —— 跑测试 → 构建制品 → 部署到预发 → 冒烟测试 → 推送生产,设置人工确认门控
- ADK Agent 交付 —— 访谈用户(Inversion)→ 生成脚手架文件(Generator)→ 验证规约(Reviewer),三个模式组合进一条 Pipeline
选对 ADK Skill 模式
每种模式回答一个不同的问题。用下表快速定位,再配合决策树做最终判断。
| 模式 | 适用场景 | 使用的目录 | 复杂度 |
|---|---|---|---|
| Tool Wrapper | Agent 需要某个库或工具的专家知识 | references/ | 低 |
| Generator | 输出每次都需要遵循固定模板 | assets/ + references/ | 中 |
| Reviewer | 代码或内容需要对标检查清单评估 | references/ | 中 |
| Inversion | Agent 动手前必须从用户处收集上下文 | assets/ | 中(多轮对话) |
| Pipeline | 工作流有顺序步骤和步骤间的验证门控 | references/ + assets/ + scripts/ | 高 |
模式可以组合。Pipeline 可以内嵌 Reviewer——doc-pipeline 的第四步加载 quality-checklist.md 对组装后的文档进行评估,就是 Reviewer 模式嵌入 Pipeline 的典型。Generator 可以用 Inversion 在产出之前先收集输入。Tool Wrapper 可以作为参考文件嵌入 Pipeline Skill。arXiv 论文”SoK: Agentic Skills”(2026 年 2 月)发现:生产系统通常组合 2-3 种模式,最常见的组合是元数据驱动的渐进式披露(对应 Tool Wrapper)加上市场分发。
不确定该选哪种时,参考这棵决策树:
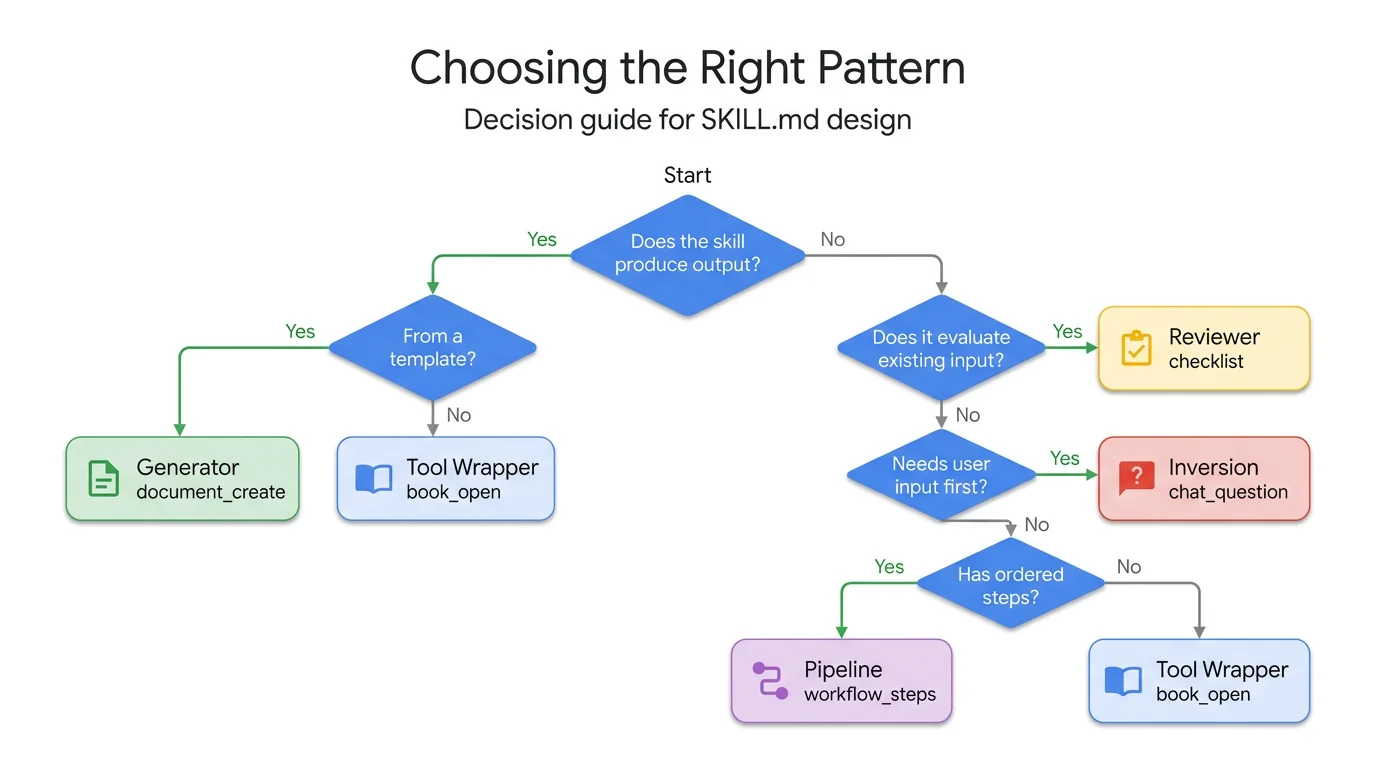 选型指南:沿是/否分支找到适合的模式。大多数 Skill 都能明确对应一种模式。
选型指南:沿是/否分支找到适合的模式。大多数 Skill 都能明确对应一种模式。
ADK Skills 生态
不需要从零写每个 Skill。Agent Skills 标准确保:任何为 Claude Code、Gemini CLI、Cursor 或30+ 兼容 Agent 编写的 Skill,在 ADK 里用 load_skill_from_dir() 直接加载即可。来源清单:
- skills.sh —— 最大的社区市场(86,000+ 次安装);用
npx skills add <owner/repo>浏览并安装任意 Skill - google-gemini/gemini-skills —— Google 官方 Gemini API Tool Wrapper Skill,覆盖构建 Gemini 应用的最佳实践
- google/adk-docs/skills —— Google 官方 ADK 开发技能包(开发指南、速查手册、评估、部署、可观测性、脚手架)—— 通过
npx skills add google/adk-docs -y -g安装 - vercel-labs/agent-skills —— Vercel 官方 React、Next.js、AI SDK 和部署模式 Skill(22K Stars)
- supabase/agent-skills —— Supabase Postgres 优化指南,覆盖查询性能、RLS 和连接管理
- anthropics/skills —— 生产级文档 Skill,支持 PowerPoint、Excel、Word 和 PDF 生成(86,500 Stars)
- VoltAgent/awesome-agent-skills —— 头部工程团队官方 Skill 精选集
- kodustech/awesome-agent-skills —— 专注架构与设计模式的 Skill 集合
在 ADK 中加载这些 Skill,克隆或复制 Skill 目录,将 load_skill_from_dir 指向该路径即可:
1
2
3
community_skill = load_skill_from_dir(
pathlib.Path(__file__).parent / "skills" / "community-skill-name"
)
目录名必须与 Skill SKILL.md frontmatter 中的
name字段完全一致——ADK 在加载时强制校验。第二篇覆盖了具体的报错行为。
外部 Skill 风险自担。 社区和第三方 Skill 未经 Google 或 ADK 团队审查背书。加载任何外部 Skill 之前,务必审查其 SKILL.md 指令、参考文件和脚本,排查意外行为、数据渗漏或提示注入风险。你对添加到 Agent 的所有 Skill 负责。
ADK Core Skills:Google 官方开发技能包
Google 发布了官方技能包,教会编码 Agent 如何编写 ADK 代码:
| Skill | 教授内容 |
|---|---|
adk-dev-guide | ADK 架构、Agent 类型、工具定义、回调 |
adk-cheatsheet | 常见 ADK 任务的快速参考模式 |
adk-eval-guide | 编写并运行 Agent 评估 |
adk-deploy-guide | 将 ADK Agent 部署到 Cloud Run 和 Vertex AI |
adk-observability-guide | ADK Agent 的追踪、日志和监控 |
adk-scaffold | 项目脚手架与目录结构 |
一行命令全局安装:
1
npx skills add google/adk-docs -y -g
这六个都是 Tool Wrapper Skill——对应上文介绍的模式。它们遵循 agentskills.io 规范,因此同样适用于 Gemini CLI、Claude Code、Cursor 等任意兼容 Agent。ADK 团队用 SkillToolset 在运行时消费的同一套 SKILL.md 格式,反过来也驱动了自身的开发工作流——一套规范,同时支撑了开发侧(编码 Agent 写 ADK 代码)和生产侧(部署 Agent 按需加载 Skill)。
常见问题
ADK 中开发的 Skill 能用在其他编码 Agent 上吗?
可以。ADK 内开发的 Skill 遵循 agentskills.io 规范,与 Gemini CLI、Antigravity、Claude Code、OpenAI Codex 共享同一套开放标准。ADK 中编写的 Skill 可以被上述任意 Agent 加载。跨客户端约定是将共享 Skill 存放在 <project>/.agents/skills/ 或 ~/.agents/skills/。外部编写的 Skill(来自社区仓库或其他团队),参考各 Agent 文档了解导入和加载方式。
一个 Agent 能挂多少个 Skill?
当前 ADK 版本(v1.25.0+,标注为 Experimental)没有硬性上限。SkillToolset 通过 process_llm_request() 在每次 LLM 调用时注入技能描述(每个约 100 token)。挂载 50 个 Skill,每次调用产生约 5,000-7,500 token 的额外开销(含 XML 封装)——对于上下文窗口 128K+ 的模型来说仍可接受。随着 Skill 数量增加,性能会平滑降级。
模式可以组合吗?
可以。Pipeline 可以内嵌 Reviewer 步骤(doc-pipeline 的第四步就是一次质量评审)。Generator 可以用 Inversion 在产出前收集输入。arXiv 论文发现,生产系统每个 Skill 的中位组合数为 2,最常见的组合是元数据驱动的渐进式披露加市场分发。
scripts/ 目录中的可执行脚本支持了吗?
通过 scripts/ 目录执行脚本在当前 pip 版本中尚未支持——ADK 文档将其列为已知限制。该能力落地后,将支持 Pipeline 和 Tool Wrapper 模式直接从 Skill 目录运行 Python 和 Shell 脚本。第三篇的”下一步”章节对此做了预演。
Skill 应该存放在项目级还是用户级?
团队共享、随代码库版本管理的 Skill 放项目级(<project>/.agents/skills/);跨所有项目使用的个人 Skill 放用户级(~/.agents/skills/)。ADK 使用显式的 load_skill_from_dir() 路径——目录由你选择,跨客户端互操作性由 Agent Skills 规范约定处理。
如何测试一个 Skill 的有效性?
agentskills.io 规范定义了评估方法论:在 evals/evals.json 中创建测试用例,有 Skill 和没有 Skill 各跑一遍,度量通过率差值。差值直接告诉你:这个 Skill 带来了多少收益,消耗了多少上下文 token。
ADK Skill 和 Tool 有什么区别?
Tool 赋予 Agent 执行动作的能力——调用 API、读取文件、查询数据库。Skill 教会 Agent 何时以及如何有效地使用这些工具。Tool 是”调用天气 API”。Skill 是”当用户询问旅行时,查询每个目的地的天气,比较结果,格式化为行程表”。Skill 建构在 Tool 之上——完整区分参见第一篇的说明。
SKILL.md 文件在 Google ADK 中如何工作?
SKILL.md 是带有 YAML 前置元数据(name、description)和结构化指令的 Markdown 文档。ADK 的 SkillToolset 通过 load_skill_from_dir() 加载它们,自动生成三个工具(list_skills、load_skill、load_skill_resource),仅在与用户请求相关时才加载完整指令。完整格式参考见第二篇。
从哪种模式开始最合适?
从 Tool Wrapper 开始——它是最简单的模式(只需指令加参考文件),也是社区采纳率最高的。把团队的编码规约或某个库的最佳实践封进一个带 references/ 目录的 SKILL.md。等到需要结构化输出或评估能力时,再进阶到 Generator 或 Reviewer。
ADK Core Skills 和 SkillToolset 是什么关系?
ADK Core Skills 是 Google 发布的官方技能包,教会编码 Agent(Gemini CLI、Claude Code、Cursor)如何正确编写 ADK 代码。它们遵循本文介绍的 Tool Wrapper 模式,使用 agentskills.io 规范。SkillToolset 是为已部署的生产 Agent 配备 Skill 的运行时 API。两者共用相同的 SKILL.md 格式:Core Skills 帮你构建 ADK Agent,SkillToolset 让你的 Agent 在运行时拥有模块化知识。
下一步
克隆配套仓库,运行 adk web .,逐一体验五种模式。从 Reviewer 开始——提交一段 Python 代码,观察 Agent 加载检查清单并产出打分报告的过程。然后把 references/review-checklist.md 换成你自己团队的编码标准。
ADK Skills 入门从第一篇开始。希望 Skill 能写 Skill,第三篇覆盖了元技能模式。本文属于 Lavi Nigam 的 Agent Engineering 系列。
参考资料
- ADK Agent 的 Skill 支持 —— SkillToolset 和渐进式披露的官方 ADK 文档
- Agent Skills 规范 —— 定义 SKILL.md 格式的开放标准,已被 30+ Agent 工具采纳
- 什么是 Agent Skills? —— agentskills.io 概念概览与采纳方清单
- 第一篇:用 SkillToolset 实现渐进式披露 —— 基础:L1/L2/L3 层级、内联 Skill
- 第二篇:文件型 Skill、外部 Skill 与 SkillToolset 内核 —— SKILL.md 格式、load_skill_from_dir、多 Skill 加载
- 第三篇:会写 Skill 的 Skill —— 元技能模式、自扩展 Agent
- 配套代码仓库 —— 本文五种模式的可运行代码
skill_toolset.py—— 含自动生成工具的 SkillToolset 源码skills_agent示例 —— 内联 + 文件型 Skill 的官方 ADK 示例- SoK: Agentic Skills——超越 LLM Agent 的工具使用 —— arXiv 论文(2026 年 2 月),归纳了 7 种系统级 Skill 设计模式
- skills.sh —— Agent Skills 目录 —— 86,000+ 次安装的社区市场
- Anthropic Skills 仓库 —— 86,500 Stars,生产级文档 Skill
- google-gemini/gemini-skills —— Google Gemini API 官方 Tool Wrapper Skill
- vercel-labs/agent-skills —— Vercel 官方 React、Next.js 和部署模式 Skill
- supabase/agent-skills —— Supabase Postgres 优化指南 Tool Wrapper Skill
- awesome-agent-skills(VoltAgent) —— 头部开发团队精选集
- awesome-agent-skills(kodustech) —— 架构与设计模式 Skill 集合
- 在 Skill 中使用脚本 —— Agent 场景下的脚本设计模式
- 评估 Skill 有效性 —— 评估方法论:测试用例、通过率差值
- Giorgio Crivellari —— 我为 Google ADK 构建了一个 Agent Skill —— Reviewer 模式将代码质量从 29% 提升到 99%
- 用 AI 编码——ADK Core Skills —— 在编码 Agent 中使用 ADK Skill 的官方教程
- ADK Core Skills(GitHub) —— 官方 ADK 开发技能包源码